RDF
What is RDF?
RDF stands for Resource Description Framework conforms to a set of W3C (Worldwide Web Consortium) standards designed to represent statements and are best for representing complex metadata and master data. They are often used for linked data, data integration, and knowledge graphs. They can represent complex concepts in a domain, or provide rich semantics and inferencing on data.RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed.RDF is a standard model for data interchange on the Web. RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed. RDF consists of “triples,” or statements, with a subject, predicate, and object that resemble any information in a contextual manner. RDF will more intuitively capture the way we think about the world as humans (as networks, not as tables), making it easier to design, capture, and query data.RDFs, As a standard supported by the W3C, it allows us to create interoperable data and systems, all using the same standard to represent and encode data. The RDF model provides a way to publish data in a standard format with well-defined semantics, enabling information exchange for any business cases which are complex to solve.
How RDF works?
RDF (Resource Description Framework) is one of the three foundational Semantic Web technologies, the other two being SPARQL and OWL (Web Ontology Language).In particular, RDF is the data model of the Semantic Web. That means that all data in Semantic Web technologies is represented as RDF. If you store Semantic Web data, it’s in RDF. If you query Semantic Web data (typically using SPARQL), it’s RDF data. If you send Semantic Web data to any enterprise systems, applications, Data science, it’s RDF.RDF describes web resources using an XML-based syntax, as well as it provides a general method to decompose web knowledge into smaller pieces by following semantic rules. RDF concerns how information is represented both in a textual form using a specific syntax and through a graph. Such graph-based representation provides insight into the data in a more structured way, and thus it better highlights relationships between facts and extends the linking structure of the Web to use URIs to name the relationship between things as well as the two ends of the link (this is usually referred to as a “triple”). Using this simple model, allows structured and semi-structured data to be mixed, exposed, and shared across different applications. This means RDF can connect to anything & derive desired outputs for business which they are facing today in real-world challenges.
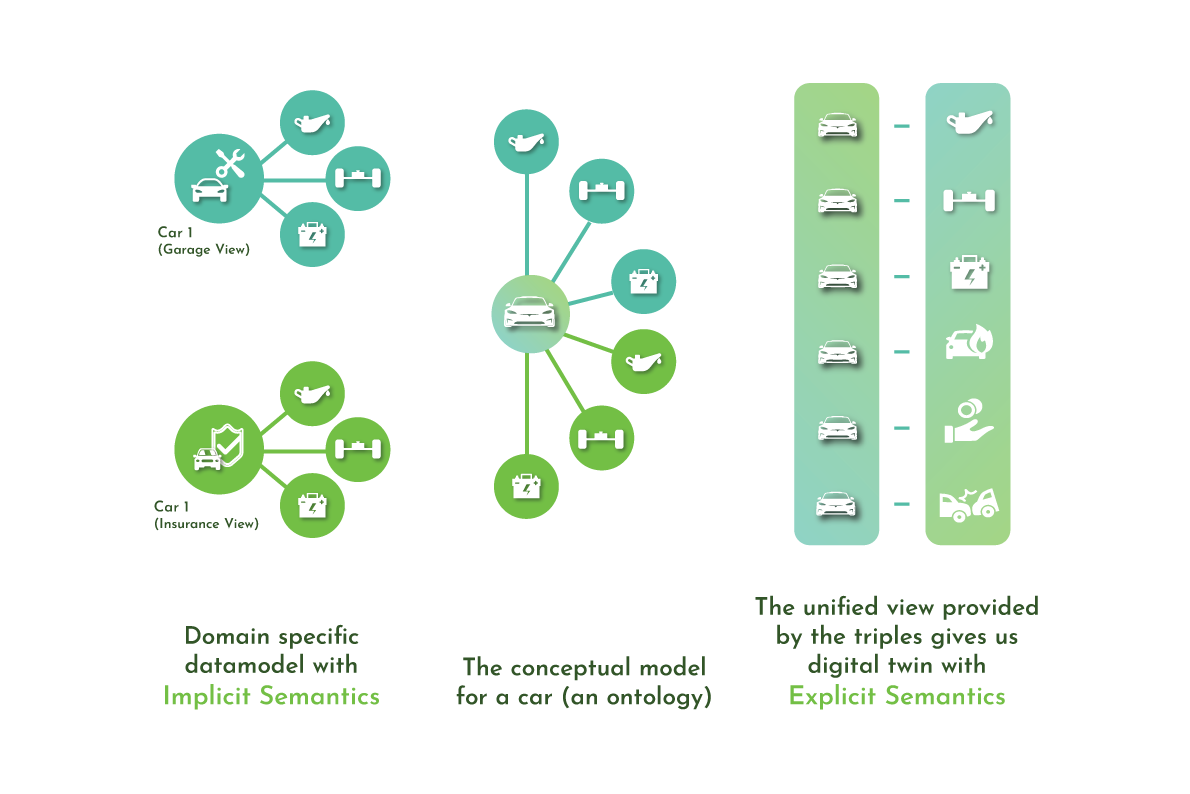
Why RDF?
Graph platforms on RDF are coined as Decision Intelligent systems. The main uses of RDF in Industry business needs are from basics like data integration, Unification, linking, standardization, and innovations to many purposes like automation, reasoning, decision triggers, Process mapping, complete visibility, Digital twins, etc…. RDF model supports reuse & repurposability options as combined: Expressivity: The standards in the Semantic Web stack – RDF(S) and OWL – allow for a fluent representation of various types of data and content: data schema, taxonomies, and vocabularies, all sorts of metadata, reference and master data. The RDF* extension makes it easy to model provenance and other structured metadata.
Formal semantics: All standards in the Semantic Web stack come with well-specified semantics, which allows humans and computers to interpret schema, ontologies, and data in an unambiguous manner.
Performance: All the specifications have been thought out, and proven in practice, to allow for efficient management of graphs of billions of facts and properties.
Interoperability: There is a range of specifications for data serialization, access (SPARQL Protocol for end-points), management (SPARQL Graph Store), and federation. The use of globally unique identifiers facilitates data integration and publishing.
Standardization: All the above are standardized through the W3C community process, to make sure that the requirements of different actors are satisfied – all the way from logicians to enterprise data management professionals and system operations teams.
What is ontologies & Taxonomies?
Ontology in RDF -
An ontology is a model which provides a formal description to human users as a shared understanding of a given domain. Ontologies are considered interpreted and processed by machines thanks to logical semantics that enables reasoning. An essential aspect of ontologies is their potential, because of the “logic inside”, ontology in RDF has Inferencing which is also an essential ingredient for automatically integrating different data sources. For instance, it is typically used to detect inconsistencies between data sources and resolve them or to analyze redundancies and optimize query evaluation. Ontologies are like skeletons for Graph platforms which include facts & constraints RDF schema is a language for writing ontologies, where RDF schema is a set of classes with certain properties using the RDF extensible knowledge representation data model, providing basic elements for the description of ontologies. ontologies in RDF allow for the creation of formalized and structured representations of knowledge domains, making it easier to share and integrate information across different applications and systems.
Taxonomy in RDF -
Taxonomy in RDF helps to organize and structure information in a way that is machine-readable, making it easier to process and analyze using automated tools and applications. Taxonomy in RDF is typically expressed using the RDF Schema (RDFS) vocabulary or the Web Ontology Language (OWL), which provides constructs for defining classes, subclasses, properties, and relationships between them. One of the central notions of any classification system is to minimize data ambiguity, or, to put it another way, to minimize the number of buckets that a given classification can be put into, preferably to the point where there are no overlaps. This is one reason that vocabularies in RDF are popular classification, and this is why most knowledge systems ultimately tend to utilize some form of hierarchy in real-world industries, one example of classification & its hierarchy can be relableta to Products in manufacturing, Drug in Pharma, Categories in E-commerce & retail, Nexus or alpha in BFSI, etc ...
What is URI (Uniform Resource Identifier) in RDF?
A Uniform Resource Identifier (URI) is a unique sequence of characters that identifies a logical or physical resource used by web technologies. URIs may be used to identify anything, including real-world objects, such as people and places, concepts, or information resources such as web pages and books. Some URIs provide a means of locating and retrieving information resources on a network (either on the Internet or on another private network, such as a computer filesystem or an Intranet).URIs are at the heart of the Web: we use them both intentionally and without realizing it every time we take advantage of the myriad possibilities the Web offers us. Their use is evolving in a number of directions, Insights into many business questions may come from surprisingly distant quarters, as well as from observation of everyday use and practice.